How AI is Replacing Us (and Reinventing) the Way We Work as a Software Consultancy
Night Mode

The Sudden Paradigm Shift
Earlier this year, I got a message. “You have to check out Claude. Look what I’ve been able to do in a couple of hours”. What followed was a link to something that, frankly, should have taken a few days to put together.
I’ve been running Upside for over eight years now. In that time, I’ve seen plenty of “this changes everything” moments. Most of them didn’t. But this one felt different. The tool was impressive on its own, sure. What got me was what it implied for everything around it. The way we design. The way we write code. The way we test. The way we think about what’s even worth building by hand anymore.
There’s a lot of anxiety in the industry right now about vibe coding replacing software developers. I partially get it. If you’ve spent years mastering a craft and someone shows you a tool that can produce a rough version of your work in minutes, that’s an uncomfortable feeling. But I’m also more excited than I’ve been in a long time. The speed of writing code is the obvious part. The real shift is which problems are worth solving, and what “good” looks like when the easy stuff becomes nearly free.
The last few months have been intense. I’m not exaggerating when I say I had a near-constant headache by the end of most days — just from trying to keep up with what’s suddenly possible. Every week brought a new workflow, a new shortcut, a new thing that used to take our team days and now took hours. The challenge was rethinking how an entire consultancy operates when the ground shifts this fast.
What follows is what actually changed for us. The good parts, the messy parts, and the parts we’re still figuring out.
From Mockups to Working Products
The design process at a consultancy like ours used to follow a familiar script. A designer would create screens in Figma - a handful of views, dummy data, a single viewport. If the client wanted to actually click through something, that meant days of extra work building an interactive prototype. And even then, what you ended up with was a polished illusion. It looked like the product but it didn’t behave like one.
That’s changed completely.
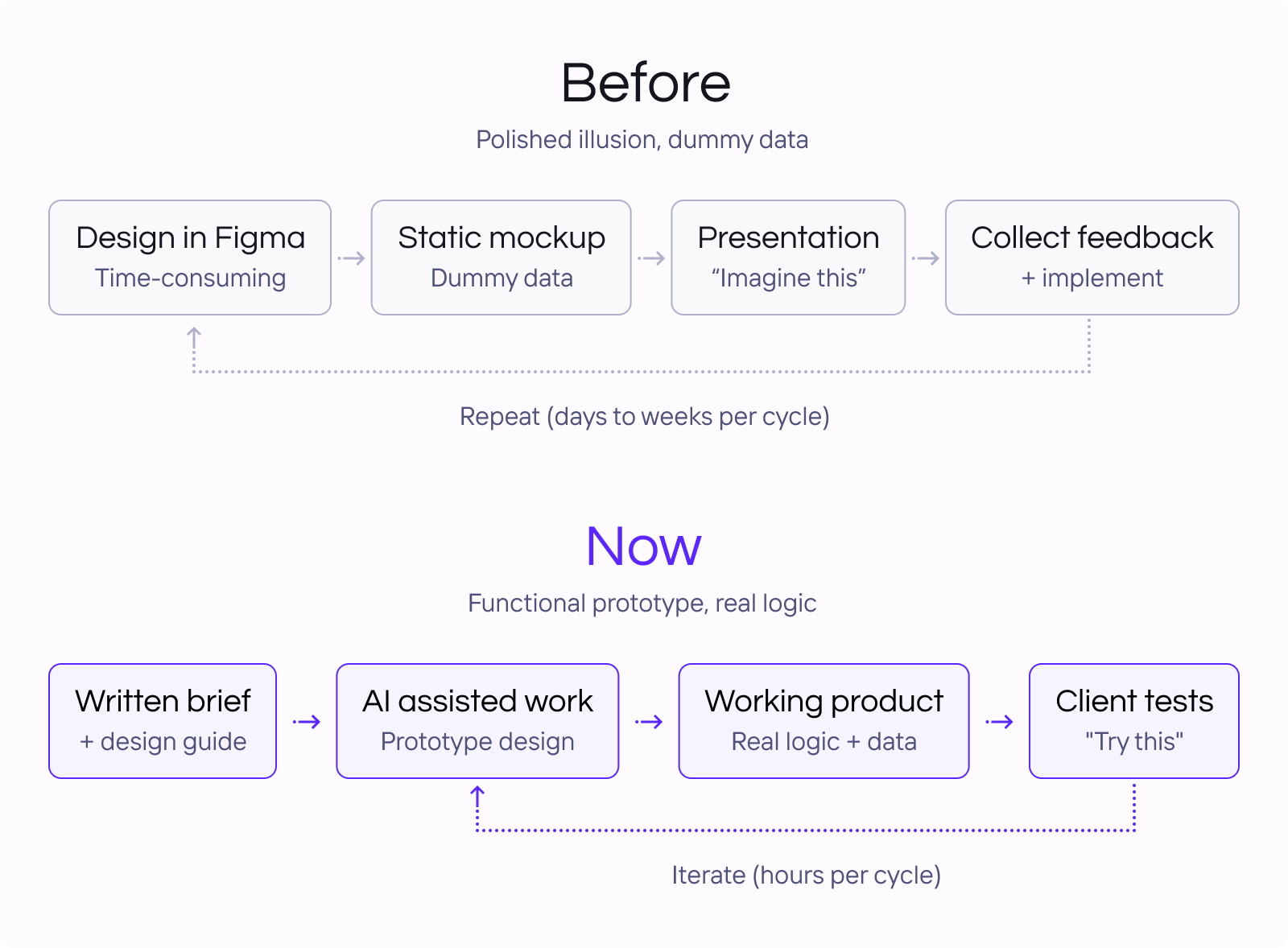
Functional prototypes, fast. Today, when we’re working on a new product concept, we can go from a design direction to a functional prototype remarkably fast. An actual working thing. We can start from Figma exports, or skip Figma altogether and go straight to Claude Code or Lovable with a written brief. Both paths get you to a real interactive prototype with real logic - something you can hand to a client and say “this is how it works”, not “this is how it will look”.
No more lorem ipsum. We’ve seen the biggest difference in data-heavy products, which is a lot of what we build. Imagine you’re designing a logistics dashboard or a platform that visualizes medical data across a map. In the old world, you’d present a static screen with placeholder numbers and hope everyone in the room could imagine how it would feel with real data, real interactions, real edge cases. Now you can hand someone a working prototype and say: play with it. Filter the data. Zoom into the map. See what happens when there are three results versus three thousand. AI is also surprisingly good at generating synthetic data that feels real, so the prototype isn’t full of placeholder nonsense - it looks and behaves like the actual product.
Better conversations, faster decisions. That shift, from “imagine this” to “try this”, changes the conversation with clients entirely. We’ve noticed people engage differently when they can actually interact with something. The discussions go deeper, the feedback is more specific, and decisions get made faster because nobody is guessing. Misunderstandings surface earlier because the prototype doesn’t lie the way a mockup can. And our designers aren’t spending their time wiring up click states - they’re focusing on the actual design problems that matter.
The Engineering Skills That Matter Now
When generating code becomes cheap, the value moves upstream. Knowing how to structure a system - how services talk to each other, where the boundaries are, what scales and what doesn’t - matters more than ever. The code itself is easier to produce. The thinking behind it isn’t.
Documentation became a superpower. Coming from a software engineering background, I never thought I’d enjoy working on documentation. But the better you are at describing a solution clearly - in writing, in structured specs, in well-organized context - the better AI tools perform. Those of our software engineers who were good at writing things down are suddenly the most productive people in the room. The skill of articulating what you want built is now directly tied to how well the machine can help you build it.
The end of the “throw hands at it” era. The low-interest-rate years rewarded a particular kind of speed. Ship fast, patch later, hire more people if something breaks. A lot of problems got solved not by thinking harder but by adding headcount. That dynamic is inverting. When AI handles the straightforward work, what’s left is the stuff that actually requires depth - and no amount of extra bodies helps if nobody understands the underlying problem.
Competing on the hard parts. If anyone can vibe-code a simple dashboard, and generating code is close to free, the differentiator is no longer the dashboard itself. It’s the part that makes software actually work in production, at scale, in a regulated industry, with real users doing unpredictable things. Security, accessibility, usability, consistency - the aspects that never got enough attention when the budget was spent on building the basics. That’s where we’ve always tried to operate, and it’s suddenly a much clearer competitive advantage.
Domain knowledge is the moat. We’ve spent years accumulating knowledge about how healthcare data works, how logistics at large companies actually runs, what makes software enterprise-ready in practice. Those tiny details - compliance edge cases, integration quirks, the stuff that only shows up after the first thousand users - never came from writing code faster. They came from doing the work. That knowledge doesn’t get automated away. If anything, it’s more valuable now because the commodity layer underneath it just got commoditized further.
Staying small was the right bet. Our strategy was never to hire a large team of developers purely for coding capacity. We kept the team senior, kept it small, and focused on the ability to deliver with fewer people who understood more. That used to feel like a constraint. Now it feels like an advantage. We don’t have a bench of developers whose primary skill was typing out React components - we have people who understand problems and can direct AI tools to solve them.
Cross-stack mobility. Here’s one that’s been practically transformative: our frontend engineers can now prototype backend changes without going deep into the backend stack. Need to adjust an API contract or expose a missing field? They can get that done. And the reverse is true - backend developers can handle simple frontend changes without waiting for a specialist. This sounds small, but in a team where blocking dependencies between people is one of the biggest productivity killers, it’s been a genuine unlock.
QA Got More Powerful
When we look at QA, a few things happened at once.
Increased code coverage. Our developers started outputting significantly more tests alongside their code. When you can generate test suites quickly, the barrier to good coverage drops. Tests that would have been skipped under time pressure now just get written.
Documentation to automation. Our QA team gained capabilities that didn’t exist before. We built a workflow around QA documentation - structured test plans, acceptance criteria, edge case inventories - that feeds directly into Claude to generate working test scripts. What used to be a document that someone would manually translate into Selenium or Playwright steps is now a starting point that produces actual automation.
Finding the “weird edge cases” is the job now. The result is that QA does different work, and more of the work that humans are uniquely good at. Our testers spend less time writing repetitive check scripts and more time doing what they’ve always been best at: reviewing the UX with fresh eyes, inventing bizarre edge cases that no spec anticipated, and applying domain knowledge to push the application to its limits before it reaches users. The kind of testing where someone looks at a healthcare form and thinks “what happens if a patient has two insurance providers and one of them has a special character in the name” - that’s still a deeply human skill, and it’s now a bigger part of the job because the routine stuff is handled.
If anything, our QA engineers are doing more interesting work now than they were a year ago.
Products We Couldn’t Have Built Before
Everything above is about doing the same work differently. What’s even more exciting is the features we’re able to build now that weren’t possible before.
Self-serve reporting. Take reporting. Dashboards used to be bespoke features - a client would request a specific view, we’d design it, build it, deploy it. A different cut of the same data three months later meant another ticket, another sprint. Now we can build reporting layers where users create their own dashboards, ask questions in natural language, execute arbitrary data transformations, and explore their data without a developer in the loop. What used to be a feature request is becoming a capability.
Dynamic data harmonization. Or consider data harmonization. With enterprise projects, you’re constantly dealing with dozens or hundreds of internal and external data sources, each with their own format, their own quirks, their own definition of what a “status” field means. Building ETL pipelines for each one used to be a domain of its own - a slow, expensive, never-ending integration project. With AI, you can handle a lot of that dynamically. The application itself can interpret and normalize incoming data instead of relying on a hand-coded pipeline for every new provider.
Unstructured inputs, structured outputs. The same applies to what I’d call wildcard inputs - the kind of unstructured, messy, real-world data that traditional systems choke on. A purchase order that arrives as a PDF scan. A product description in free text that needs to be categorized. A customer email that contains an implicit request buried in three paragraphs. These used to require either human processing or months of custom NLP work. Now they’re solvable problems at a fraction of the effort.
We can propose solutions now that would have been out of scope a year ago. The conversation with clients shifted from “here’s what we can build within your budget” to “here’s what’s actually possible now”.
What’s Not Working (Yet)
Some of this we’re still figuring out. Here’s what we’re trying to find our way around.
Code review fatigue is real. When developers produce more code, faster, someone still has to review it. The thing about AI-generated code is that it tends to be technically correct - it compiles, it passes basic checks - but it doesn’t always do what you actually meant. Reviewing it requires a different kind of attention. You’re looking for subtle misalignment with how your system is supposed to work. That’s mentally draining in a way that reviewing a colleague’s handwritten code isn’t.
The rhythm of the work changed. Software engineering used to be a slow, deliberate craft. You’d spend time understanding the problem, then carefully write a solution, then debug it methodically. There was a certain meditative quality to it. That dynamic has shifted. The thinking part is still there - arguably more important than ever - but the execution happens in bursts. You iterate fast, generate, review, adjust, generate again. The difficult bugs still land on your desk, but the simple ones get handled on autopilot. It’s more productive, but it’s also more cognitively demanding in a different way. Some days it feels like your brain is the bottleneck, not the tooling.
Pull requests got unwieldy. When it’s easy to build a feature end to end in one session, the natural instinct is to ship it as one PR. But our whole workflow is built around small, reviewable pull requests - and that discipline is clashing with the new pace. PRs grew significantly in size, which means code reviews take longer, context-switching is harder, and the feedback loop slows down in exactly the place where it used to be fast. We’re still figuring out the right balance here.
The pace outran our capacity. This is the strangest one to admit. Projects are moving faster than before, and the main blocker is no longer technical. It’s us. Our ability to think through decisions, maintain context across a codebase that’s growing quickly, and make good judgment calls under time pressure - that’s the constraint now. That, and the token limits.
What Comes Next

I don’t know exactly where this goes. Nobody does, and I’d be skeptical of anyone who claims otherwise. But I do know how it feels right now, and it feels like the most interesting moment in the eight years I’ve been running Upside. The work is changing - not disappearing, not degrading, but genuinely changing shape. We spend less time on the mechanical parts of building software and more time on the problems that matter: architecture decisions, domain-specific nuance, advising clients on what to build and why. The role is shifting from “we write your code” toward “we help you make the right technical decisions, and then we execute them fast”. For a consultancy, that’s a better place to be.
Being a small team used to come with obvious limitations. There were projects we couldn’t take on, timelines we couldn’t meet, scope we couldn’t cover. A lot of those constraints are softer now. We can execute at a pace that would have required a much larger team a year ago - not because the work got easier, but because the ratio of thinking to typing changed in our favor.
There’s a lot of uncertainty in all of this, obviously. The tools are evolving weekly. The workflows we’re building today might look completely different in six months. And the industry is still figuring out what it means when the floor of “good enough” software rises for everyone. But for now, I’d rather be adapting than watching. And I’d much rather have a headache from trying to keep up than from wondering whether we should have started sooner.
Explore More Blog Posts

What is an agentic AI system for e-commerce?
An agentic AI system for e-commerce is software that autonomously plans and executes multi-step tasks across your commerce stack - from product discovery to order processing - without step-by-step human instruction. It uses large language models (LLMs) to reason, decide, and act on your behalf, grounded in your own product data.

Field notes from HIMSS Europe 2026 in Copenhagen
My smartwatch knows more about my body on an average Tuesday than my hospital does. It tracks how I slept, how hard my heart worked on a run, whether I am trending in the wrong direction before I feel anything at all. The institution with the doctors, the scanners and a century of clinical knowledge mostly meets me when something has already gone wrong.

The AI Design Gap: Moving Beyond One-Way Generation
There are plenty of tools capable of generating code from designs or directly from prompts. In theory, this looks like a dream scenario. It drastically shortens the journey from design to frontend development. The handoff is quicker, the design is easier to implement, and everyone involved is happier. Right?